
Как найти максимальный байт в java-файле
Обновлено: 02.05.2024
Экземпляры этого класса поддерживают как чтение, так и запись в файл с произвольным доступом. Файл с произвольным доступом ведет себя как большой массив байтов, хранящийся в файловой системе. Существует разновидность курсора или индекса в подразумеваемом массиве, который называется указатель файла; операции ввода читают байты, начиная с указателя файла, и перемещают указатель файла дальше прочитанных байтов. Если файл произвольного доступа создан в режиме чтения/записи, то доступны и операции вывода; операции вывода записывают байты, начиная с указателя файла, и продвигают указатель файла за пределы записанных байтов. Операции вывода, которые записывают за текущий конец подразумеваемого массива, вызывают расширение массива. Указатель файла можно прочитать с помощью метода getFilePointer и установить с помощью метода seek.
В целом для всех подпрограмм чтения в этом классе справедливо то, что если конец файла достигается до того, как будет прочитано желаемое количество байтов, генерируется исключение EOFException (своего рода IOException ). Если какой-либо байт не может быть прочитан по какой-либо причине, кроме конца файла, генерируется исключение IOException, отличное от EOFException. В частности, исключение IOException может быть вызвано, если поток был закрыт.
Сводка конструктора
Создает файловый поток с произвольным доступом для чтения и, при необходимости, для записи в файл, указанный аргументом File.
Создает файловый поток с произвольным доступом для чтения и, при необходимости, для записи в файл с указанным именем.
Краткое описание метода
| Модификатор и тип | Метод и описание |
|---|---|
| void | close() |
Устанавливает смещение указателя файла, измеряемое от начала этого файла, при котором происходит следующее чтение или запись.
Записывает b.length байтов из указанного массива байтов в этот файл, начиная с текущего указателя файла.
Преобразует аргумент типа double в тип long с помощью метода doubleToLongBits в классе Double , а затем записывает значение типа long в файл в виде восьмибайтового значения, старшим байтом вперед.
Преобразует аргумент типа float в тип int с помощью метода floatToIntBits в классе Float , а затем записывает значение типа int в файл в виде четырехбайтового числа, старшим байтом вперед.
Методы, унаследованные от класса java.lang.Object
Сведения о конструкторе
Файл произвольного доступа
Создает файловый поток с произвольным доступом для чтения и, при необходимости, для записи в файл с указанным именем. Создается новый объект FileDescriptor для представления подключения к файлу.
Аргумент mode указывает режим доступа, в котором файл должен быть открыт. Допустимые значения и их значения указаны для конструктора RandomAccessFile(File,String).
При наличии диспетчера безопасности его метод checkRead вызывается с аргументом имени в качестве аргумента, чтобы проверить, разрешен ли доступ для чтения к файлу. Если режим разрешает запись, метод менеджера безопасности checkWrite также вызывается с аргументом имени в качестве аргумента, чтобы проверить, разрешен ли доступ для записи в файл.
Файл произвольного доступа
Создает файловый поток с произвольным доступом для чтения и, при необходимости, для записи в файл, указанный аргументом File. Новый объект FileDescriptor создается для представления этого подключения к файлу.
Значение
< /tr> Значение
"r" Открыть только для чтения. Вызов любого из методов write результирующего объекта вызовет исключение IOException. "rw" Открыть для чтения и записи. Если файл еще не существует, будет предпринята попытка его создания. "rws" Открыт для чтения и записи, как и в случае с "rw", а также требует, чтобы каждое обновление содержимого файла или метаданных записывалось синхронно на базовое устройство хранения. "rwd" Открыть для чтения и записи, как с "rw", а также требуют, чтобы каждое обновление содержимого файла записывалось синхронно на базовое устройство хранения.
Режимы "rws" и "rwd" работают так же, как метод force(boolean) класса FileChannel, передавая аргументы true и false соответственно, за исключением того, что они всегда применяются к каждой операции ввода-вывода и поэтому часто более эффективны. Если файл находится на локальном запоминающем устройстве, то при возврате вызова метода этого класса гарантируется, что все изменения, внесенные в файл этим вызовом, будут записаны на это устройство.Это полезно для обеспечения того, чтобы важная информация не была потеряна в случае сбоя системы. Если файл не находится на локальном устройстве, такая гарантия не предоставляется.
Режим "rwd" можно использовать для уменьшения количества выполняемых операций ввода-вывода. Использование "rwd" требует только записи в хранилище обновлений содержимого файла; использование "rws" требует обновления как содержимого файла, так и его метаданных для записи, что обычно требует как минимум еще одной низкоуровневой операции ввода-вывода.
При наличии диспетчера безопасности его метод checkRead вызывается с указанием пути к файлу в качестве аргумента, чтобы проверить, разрешен ли доступ для чтения к файлу. Если режим разрешает запись, метод менеджера безопасности checkWrite также вызывается с аргументом пути, чтобы узнать, разрешен ли доступ для записи к файлу.
Сведения о методе
получить FD
получить канал
Позиция возвращаемого канала всегда будет равна смещению указателя файла этого объекта, возвращаемому методом getFilePointer. Изменение смещения указателя файла этого объекта, будь то явно или путем чтения или записи байтов, изменит положение канала и наоборот. Изменение длины файла с помощью этого объекта изменит длину, видимую через файловый канал, и наоборот.
Читает байт данных из этого файла. Байт возвращается как целое число в диапазоне от 0 до 255 (0x00-0x0ff). Этот метод блокируется, если вход еще не доступен.
Хотя RandomAccessFile не является подклассом InputStream , этот метод ведет себя точно так же, как метод InputStream.read() InputStream .
Считывает до len байт данных из этого файла в массив байтов. Этот метод блокируется до тех пор, пока не будет доступен хотя бы один байт ввода.
Хотя RandomAccessFile не является подклассом InputStream , этот метод ведет себя точно так же, как метод InputStream.read(byte[], int, int) InputStream .
Считывает до b.length байт данных из этого файла в массив байтов. Этот метод блокируется до тех пор, пока не будет доступен хотя бы один байт ввода.
Хотя RandomAccessFile не является подклассом InputStream , этот метод ведет себя точно так же, как метод InputStream.read(byte[]) InputStream .
Читать полностью
Читает b.length байтов из этого файла в массив байтов, начиная с текущего указателя файла. Этот метод многократно считывает файл до тех пор, пока не будет прочитано запрошенное количество байтов. Этот метод блокируется до тех пор, пока не будет прочитано запрошенное количество байтов, не будет обнаружен конец потока или не возникнет исключение.
Читать полностью
Читает ровно len байт из этого файла в массив байтов, начиная с текущего указателя файла. Этот метод многократно считывает файл до тех пор, пока не будет прочитано запрошенное количество байтов. Этот метод блокируется до тех пор, пока не будет прочитано запрошенное количество байтов, не будет обнаружен конец потока или не возникнет исключение.
пропустить байты
Этот метод может пропускать меньшее количество байтов, возможно, ноль. Это может быть результатом любого из ряда условий; достижение конца файла до того, как будут пропущены n байтов, — это только одна возможность. Этот метод никогда не генерирует исключение EOFException. Возвращается фактическое количество пропущенных байтов. Если n отрицательное, байты не пропускаются.
написать
написать
Записывает b.length байтов из указанного массива байтов в этот файл, начиная с текущего указателя файла.
написать
получить указатель файла
Устанавливает смещение указателя файла, измеряемое от начала этого файла, при котором происходит следующее чтение или запись. Смещение может быть установлено за пределами конца файла. Установка смещения за конец файла не меняет длину файла. Длина файла изменится только путем записи после того, как будет установлено смещение за конец файла.
длина
установить длину
Если текущая длина файла, возвращаемая методом length, больше аргумента newLength, файл будет усечен. В этом случае, если смещение файла, возвращенное методом getFilePointer, больше, чем newLength, то после возврата этого метода смещение будет равно newLength .
Если текущая длина файла, возвращаемая методом length, меньше аргумента newLength, файл будет расширен. В этом случае содержимое расширенной части файла не определяется.
закрыть
Закрывает этот файловый поток с произвольным доступом и освобождает все системные ресурсы, связанные с этим потоком. Закрытый файл с произвольным доступом не может выполнять операции ввода или вывода и не может быть повторно открыт.
Если у этого файла есть связанный канал, этот канал также закрывается.
readBoolean
Читает логическое значение из этого файла. Этот метод считывает один байт из файла, начиная с текущего указателя файла. Значение 0 представляет false . Любое другое значение представляет собой true .Этот метод блокируется до тех пор, пока не будет прочитан байт, не будет обнаружен конец потока или не возникнет исключение.
байт чтения
Читает восьмибитное значение со знаком из этого файла. Этот метод считывает байт из файла, начиная с текущего указателя файла. Если прочитанный байт равен b , где 0
Этот метод блокируется до тех пор, пока не будет прочитан байт, не будет обнаружен конец потока или пока не возникнет исключение.
readUnsignedByte
Читает из этого файла восьмибитное число без знака. Этот метод считывает байт из этого файла, начиная с текущего указателя файла, и возвращает этот байт.
Этот метод блокируется до тех пор, пока не будет прочитан байт, не будет обнаружен конец потока или пока не возникнет исключение.
краткое чтение
Читает из этого файла 16-битное число со знаком. Метод считывает два байта из этого файла, начиная с текущего указателя файла. Если прочитаны два байта по порядку, это b1 и b2 , где каждое из двух значений находится в диапазоне от 0 до 255 включительно, тогда результат будет равен:
Этот метод блокируется до тех пор, пока не будут прочитаны два байта, не будет обнаружен конец потока или не возникнет исключение.
readUnsignedShort
Читает из этого файла 16-битное число без знака. Этот метод считывает два байта из файла, начиная с текущего указателя файла. Если прочитаны байты по порядку, это b1 и b2 , где 0
Этот метод блокируется до тех пор, пока не будут прочитаны два байта, не будет обнаружен конец потока или не возникнет исключение.
прочитатьсимвол
Читает символ из этого файла. Этот метод считывает два байта из файла, начиная с текущего указателя файла. Если прочитаны байты по порядку, это b1 и b2 , где 0
Этот метод блокируется до тех пор, пока не будут прочитаны два байта, не будет обнаружен конец потока или не возникнет исключение.
Чтение
Читает из этого файла 32-битное целое число со знаком. Этот метод считывает 4 байта из файла, начиная с текущего указателя файла. Если байты прочитаны по порядку, это b1 , b2 , b3 и b4 , где 0
Этот метод блокируется до тех пор, пока не будут прочитаны четыре байта, не будет обнаружен конец потока или не возникнет исключение.
Долгое чтение
тогда результат равен:
Этот метод блокируется до тех пор, пока не будут прочитаны восемь байтов, не будет обнаружен конец потока или не возникнет исключение.
чтение с плавающей запятой
Читает число с плавающей запятой из этого файла. Этот метод считывает значение int, начиная с текущего указателя файла, как будто с помощью метода readInt, а затем преобразует это целое число в число с плавающей запятой с помощью метода intBitsToFloat в классе Float .
Этот метод блокируется до тех пор, пока не будут прочитаны четыре байта, не будет обнаружен конец потока или не возникнет исключение.
Двойное чтение
Читает двойное значение из этого файла. Этот метод считывает длинное значение, начиная с текущего указателя файла, как будто с помощью метода readLong, а затем преобразует это длинное значение в двойное с помощью метода longBitsToDouble в классе Double .
Этот метод блокируется до тех пор, пока не будут прочитаны восемь байтов, не будет обнаружен конец потока или не возникнет исключение.
строка чтения
Читает следующую строку текста из этого файла. Этот метод последовательно считывает байты из файла, начиная с текущего указателя файла, пока не достигнет знака конца строки или конца файла. Каждый байт преобразуется в символ путем взятия значения байта для младших восьми битов символа и установки старших восьми битов символа равными нулю. Поэтому этот метод не поддерживает полный набор символов Unicode.
Строка текста заканчивается символом возврата каретки ( '\r' ), символом новой строки ( '\n' ), символом возврата каретки, за которым сразу следует символ новой строки, или концом файла . Символы конца строки отбрасываются и не включаются в возвращаемую строку.
Этот метод блокируется до тех пор, пока не будет прочитан символ новой строки, возврат каретки и байт, следующий за ним (чтобы узнать, является ли он новой строкой), не будет достигнут конец файла или не возникнет исключение.
прочитатьUTF
Читаются первые два байта, начиная с текущего указателя файла, как если бы это было readUnsignedShort . Это значение дает количество следующих байтов в закодированной строке, а не длину результирующей строки. Следующие байты затем интерпретируются как байты, кодирующие символы в модифицированном формате UTF-8, и преобразуются в символы.
Этот метод блокируется до тех пор, пока не будут прочитаны все байты, не будет обнаружен конец потока или пока не возникнет исключение.
написать логическое значение
Записывает логическое значение в файл как однобайтовое значение. Значение true записывается как значение (byte)1 ; значение false записывается как значение (byte)0 . Запись начинается с текущей позиции указателя файла.
запись байта
Записывает байт в файл как однобайтовое значение. Запись начинается с текущей позиции указателя файла.
написатьШорт
Записывает короткое замыкание в файл в виде двух байтов, старшим байтом вперед.Запись начинается с текущей позиции указателя файла.
написатьсимвол
Записывает char в файл как двухбайтовое значение, старший байт идет первым. Запись начинается с текущей позиции указателя файла.
записатьInt
Записывает в файл целое число в виде четырех байтов, старший байт идет первым. Запись начинается с текущей позиции указателя файла.
длинная запись
Записывает в файл длинное значение в виде восьми байтов, старшим байтом вперед. Запись начинается с текущей позиции указателя файла.
запись с плавающей запятой
Преобразует аргумент типа float в тип int с помощью метода floatToIntBits в классе Float , а затем записывает значение типа int в файл в виде четырехбайтового числа, старшим байтом вперед. Запись начинается с текущей позиции указателя файла.
написатьДвойной
Преобразует аргумент типа double в тип long с помощью метода doubleToLongBits в классе Double , а затем записывает это значение типа long в файл в виде восьмибайтовой величины, старшим байтом вперед. Запись начинается с текущей позиции указателя файла.
записать байты
Записывает строку в файл в виде последовательности байтов. Каждый символ в строке записывается последовательно, отбрасывая его старшие восемь битов. Запись начинается с текущей позиции указателя файла.
написатьсимволы
Записывает в файл строку в виде последовательности символов. Каждый символ записывается в поток вывода данных как бы методом writeChar. Запись начинается с текущей позиции указателя файла.
записать UTF
Сначала в файл записываются два байта, начиная с текущего указателя файла, как если бы метод writeShort задавал количество следующих байтов. Это значение представляет собой количество фактически записанных байтов, а не длину строки. После длины каждый символ строки выводится последовательно, используя модифицированную кодировку UTF-8 для каждого символа.
- Обзор:
- Вложенный |
- Поле | |
- Подробности:
- Поле | |
Сообщите об ошибке или функции.
Дополнительные справочные материалы по API и документацию для разработчиков см. в документации по Java SE. Эта документация содержит более подробные описания, предназначенные для разработчиков, с концептуальными обзорами, определениями терминов, обходными путями и примерами рабочего кода.
Авторские права © 1993, 2020, Oracle и/или ее дочерние компании. Все права защищены. Использование регулируется условиями лицензии. Также ознакомьтесь с политикой распространения документации.
Здравствуйте, ребята, Java-программисты часто сталкиваются со сценариями в реальном программировании, где им нужно загрузить данные из файла в массив байтов, это может быть текстовый или двоичный файл. Одним из примеров является преобразование содержимого файла в строку для отображения. К сожалению, класс File в Java, который используется для представления как файлов, так и каталогов, не имеет метода toByteArray() . Он содержит только путь и позволяет выполнять определенные операции, такие как открытие и закрытие файла, но не позволяет напрямую преобразовывать файл в массив байтов. В любом случае, не нужно беспокоиться, так как есть несколько других способов чтения файла в массив байтов, и вы узнаете о них в этом руководстве по файлам Java.
Если вы, как и я, являетесь поклонником Apache commons и Google Guava, то, возможно, вы уже знакомы с однострочным кодом, который может быстро прочитать файл в массив байтов; если нет, то сейчас самое время изучить эти API.
В этом руководстве мы рассмотрим 7 различных примеров чтения файла в массив байтов, некоторые с использованием сторонних библиотек, а другие с использованием базовых библиотек Java JDK 6 и JDK 7.
В зависимости от вашего выбора вы можете использовать любой из следующих методов для преобразования данных файла в байты. Следует иметь в виду, что вы делаете с массивом байтов; если вы создаете строку из массива байтов, остерегайтесь кодировки символов. Вам может потребоваться узнать правильную кодировку символов, прочитав информацию метаданных, такую как Content-Type страниц HTML и документов XML.
При чтении XML-документов не рекомендуется сначала читать XML-файл и сохранять его в виде строки. Вместо этого лучше передать InputStream парсерам XML, и они сами правильно вычислят кодировку.
Еще одна вещь, которую следует отметить, это то, что вы не можете читать файлы размером более 2 ГБ в однобайтовый массив, для этого вам нужны массивы из нескольких байтов. Это ограничение связано с тем, что индекс массива в Java имеет тип int, максимальное значение которого равно 2 147483647 , что примерно эквивалентно 2 ГБ.
Кстати, я ожидаю, что вы знакомы с основами программирования на Java и Java API в целом. Если вы совсем новичок, я предлагаю вам сначала пройти эти лучшие онлайн-курсы по Java, чтобы узнать больше об основных основах Java, а также о таких жемчужинах Java API.
7 способов чтения файла в массив байтов в Java
Не теряя больше времени, вот все семь способов загрузить файл в массив байтов в Java:
1) Использование Apache Commons IOUtils
Это один из самых простых способов чтения данных файла в массив байтов, если вы не ненавидите сторонние библиотеки. Это продуктивно, потому что вам не нужно писать код с нуля, беспокоиться об обработке исключений и т. д.
The IOUtils.toByteArray(InputStream input) Получает содержимое InputStream в виде byte[]. Этот метод также буферизует ввод внутри, поэтому нет необходимости использовать BufferedInputStream , но он не является нулевым. Он генерирует исключение NullPointerException, если входное значение равно null .
2) Использование Apache Commons FileUtils
3) Использование FileInputStream и JDK
Это классический способ чтения содержимого файла в массив байтов. Не забудьте закрыть поток после завершения. Вот код для чтения файла в массив байтов с использованием класса FileInputStream в Java:
В производственной среде используйте блок finally, чтобы закрыть потоки для освобождения файловых дескрипторов.
4) Использование класса Google Guava Files
Класс Files Google Guava предоставляет служебные методы для работы с файлами, такие как преобразование файлов в массив байтов, в строку с указанной кодировкой, копирование, перемещение и т. д. Метод Files.toByteArray() считывает все байты из файла в массив байтов и генерирует исключение IllegalArgumentException, если размер файла превышает максимально возможный массив байтов (2^31 - 1).
У такого подхода чтения содержимого файлов в байтовый массив есть несколько преимуществ, во-первых, вам не нужно изобретать велосипед. Во-вторых, он использует NIO для чтения файла, который работает лучше, чем потоковый ввод-вывод. Вам также не нужно беспокоиться об обработке исключений и закрытии потоков, как это делает за вас Гуава.
5) Использование утилиты ByteStreams от Guava
Класс ByteStreams в Guava предоставляет служебные методы для работы с байтовыми массивами и потоками ввода-вывода. toByteArray() принимает InputStream и считывает все байты в массив байтов, но не закрывает поток, поэтому вам нужно закрыть его самостоятельно.
Это одна из причин, по которой я не предпочитаю этот метод, пример Java 7, который мы видели в предыдущем разделе, заботится о закрытии потоков.
Кстати, если вы используете среду ограничений Java в памяти, такую как Android, рассмотрите возможность использования обфускатора, такого как proguard, для удаления неиспользуемых классов из сторонних библиотек. Например, Guava по умолчанию добавляет в APK более 2 МБ. Но с Proguard он составляет около 250 КБ
6) Использование файлов JDK 7 NIO и пути
Если вы используете Java 7, то это лучший способ преобразовать файл в массив байтов. Он позволяет читать все байты из файла и записывать их в массив байтов. Все, что вам нужно знать, это путь к файлу.
Вот пример кода для чтения файла в Java 7:
Самое большое преимущество этого подхода заключается в том, что для него не требуются сторонние библиотеки. Это также статический метод, что делает его очень удобным. Это также гарантирует, что файл будет закрыт, когда все байты будут прочитаны или возникнет ошибка ввода-вывода или другое исключение времени выполнения. Кое-что, чего не хватало Java по сравнению с первой версией.
Кстати, этот метод предназначен только для простого использования, когда удобно читать все байты в массив байтов. Он не предназначен для чтения больших файлов и выдает OutOfMemoryError, если не может быть выделен массив нужного размера, например, файл больше 2 ГБ.
Кстати, если у вас есть только объект File, а не Path, вы также можете использовать File.toPath() для преобразования File в Path в JDK 1.7. Если вы хотите узнать больше, я предлагаю вам ознакомиться с основными курсами Java на Udemy для углубленного изучения.

7) Использование RandomAccessFile в Java
Вы также можете использовать RandomeAccessFile для преобразования File в массив байтов, как показано ниже, хотя вы также можете использовать метод read(byte[]), лучше использовать readFully.
Также обратите внимание, что RandomAccessFile не является потокобезопасным. Поэтому в некоторых случаях может потребоваться синхронизация.
И последнее, часть кода здесь некачественная, так как они не обрабатывают исключения должным образом. В реальном мире весь код обработки файлов должен закрывать потоки в блоке finally, чтобы освободить дескриптор файла, связанный с этим, невыполнение этого требования может привести к ошибке java.io.IOException: Too many open files.
Иногда вы можете ожидать, что библиотеки, такие как Apache commons IO, будут правильно закрывать потоки, как показано ниже из фрагмента кода из класса FileUtils Apache Commons IO, методы closeQuietly() закрывают поток, игнорируя пустые значения и исключения.
публичный статический байт [ ] readFileToByteArray (файловый файл) вызывает исключение IOException <
но это не всегда так, поскольку метод ByteStreams.toByteArray Google Guava не закрывает поток.Перед использованием того или иного метода в рабочем коде лучше проверить документацию. В общем, лучше использовать JDK API, если он доступен, и поэтому хорошее знание JDK имеет большое значение для того, чтобы стать опытным Java-программистом. Если вы хотите узнать больше, я предлагаю вам присоединиться к курсам Java Fundamentals Part 1 и 2 на Pluralsight. В этом месяце это бесплатно, в противном случае вам придется заплатить за членство.

Программа Java для чтения файла в массив байтов в Java
Вот наша полная программа на Java для чтения файла в массив байтов на Java. Это объединяет все 6 подходов, которые я показал выше. Вы можете скопировать и вставить этот пример и запустить его в своей любимой среде IDE, такой как Eclipse, NetBeans или IntelliJIDEA.
Это все в этом руководстве по 7 способам чтения файла в массив байтов в Java. Теперь вы знаете, что существует несколько способов чтения файла в Java, некоторые с использованием сторонних библиотек, таких как Apache Commons IO, Google Guava, Apache MINA и другие, просто используя стандартные классы ввода-вывода файлов JDK. В зависимости от ваших требований вы можете использовать любое из этих решений для чтения данных файла в байт в Java. Следите за кодировкой символов, если вы конвертируете массив байтов в строку.
Кроме того, помните, что массив в Java может содержать только ограниченный объем данных, поскольку его длина не может превышать Integer.MAX_VALUE (2 ГБ). Таким образом, вы не можете преобразовать большой файл в однобайтовый массив, хотя вы можете читать большие данные с помощью входного потока, вам нужно обрабатывать их фрагментами или использовать многобайтовые массивы.
Если вам понравилась эта статья и вы хотите узнать больше об улучшенном файловом вводе-выводе в последней версии Java, ознакомьтесь со следующими руководствами:
- Полная дорожная карта Java-разработчика (руководство)
- 3 способа чтения файла построчно в Java 8 (примеры)
- 10 курсов по изучению Java для начинающих (курсы)
- Как прочитать текстовый файл построчно с помощью BufferedReader в Java? (ответ)
- 15 вещей, которым программисты Java могут научиться в 2020 году (статья)
- Как использовать файл с отображением памяти в Java? (ответ)
- Пять основных навыков, которые помогут пройти собеседование по программированию (навыки)
- Как читать XML-файл как строку в Java? (учебник)
- Как читать/записывать файлы Excel (как XLS, так и XLSX) в Java с помощью Apache POI? (учебник)
- 2 способа анализа CSV-файла в Java? (ответ)
- Как удалить каталог с файлами в Java? (ответ)
- Как анализировать XML-файл в Java с помощью парсера SAX? (руководство)
- Как преобразовать JSON в объект в Java? (пример)
- Как читать XML-файл в Java с помощью синтаксического анализатора JDOM? (учебник)
- Как выполнить синтаксический анализ большого файла JSON с помощью Jackson Streaming API? (пример)
- Как прочитать файл в одну строку в Java 8? (пример)
- Как скопировать файл в Java? (пример)
- Как сгенерировать контрольную сумму MD5 для файла в Java? (решение)
- Как читать/записывать RandomAccessFile в Java? (пример)
P.S. – Если вы новичок в мире Java и хотите углубленно изучить и освоить программирование на Java и ищете бесплатные курсы для начала, вы также можете ознакомиться со списком бесплатных курсов Java для программистов на Medium.
Я наткнулся на это упражнение, в котором у меня есть наиболее часто встречающиеся байты в файле и я отображаю их. У меня два вопроса:
1 – Должен ли я использовать свое время, чтобы попытаться решить эту проблему, или это просто головокружение, которое не поможет в будущем?
2 – я попробовал вариант без HashMaps. Я создал массив байтов, отсортировал его, нашел наиболее часто встречающийся элемент и частоту, а затем снова зациклился, чтобы добавить любые элементы с максимальной частотой в результат ArrayList. Но упражнение не проходит автоматическую проверку. Вот код. Делает ли код то, что я думаю? Добавить все наиболее часто встречающиеся байты в результат ArrayList?
Также приветствуются любые комментарии о неправильной практике или различных подходах:

Маршал
Пабло Агирре написал: . . . 1 - Должен ли я использовать свое время, чтобы попытаться решить эту проблему? . .
Если вы не заняты всем остальным, думаю, да. Стоит напрячь свой мозг, и даже если вы больше никогда не будете использовать этот код, это упражнение потренирует ваши навыки решения проблем.
Надеюсь, это не значит, что вы догадывались. Вы можете угадать 1000000×, и одно из предположений будет правильным, или, как сказал Уинстон, вы можете разработать свое приложение, и оно будет правильным с первого раза.
Я создал массив байтов, отсортировал его, нашел наиболее часто встречающийся элемент и частоту, а затем снова зациклился, чтобы добавить любые элементы с максимальной частотой в результат ArrayList.
Ого, это выглядит сложно. Я автоматически предполагаю, что все сложное неправильно, даже не читая его
Но упражнение не проходит автоматическую проверку.
Что делать с автоматической проверкой? Сообщите нам, откуда появился вопрос (соответствующие часто задаваемые вопросы), тогда мы сможем проверить вопрос и попробовать сами.
<блочная цитата>. . . Делает ли код то, что я думаю? . . .
Любые комментарии . . . также приветствуется
Слава богу, кто-то знает, как делать отступы в своем коде
Я предлагаю вам создать объект с именем файла в качестве поля. Дайте ему методы для чтения байтов, подсчета отдельных байтов, поиска максимума и отображения наиболее часто встречающегося байта. Боюсь, я не понимаю вашу технику подсчета.

Привет! Спасибо за ответ. Я очень ценю ваши отзывы.
Упражнение взято с CodeGym. Это лучший ресурс, который я нашел до сих пор, потому что он основан на упражнениях и проектах, и так я лучше всего учусь. Решения учащегося автоматически проверяются некоторым подключаемым модулем IntelliJ, который у них есть. Не уверен, что вы можете открыть, если вы не вошли в систему: упражнение Codegym
Да, мое решение слишком сложное, я использовал решение, основанное на HashMap, и оно все упростило. Но я попробую создать объект, как вы предложили.
Хранитель салуна
Нахождение количества байтов упрощает задачу, поскольку для байта существует только 256 возможных значений, поэтому у вас может быть массив из 256 целых чисел, содержащих количество. Без сортировки. Нет необходимости загружать весь файл в память.
Try-with-resources обрабатывает вызов close() "за кулисами" более последовательным и надежным способом, чем вы могли бы написать.
Шериф
Пабло Агирре писал: 1. Должен ли я использовать свое время, чтобы попытаться решить эту проблему, или это просто головоломка, которая не поможет в будущем?
Если вы когда-либо наблюдали, как спортсмены тренируются/тренируются, вы могли видеть, как они переворачивают шину тяжелого грузовика, размахивают тяжелой веревкой или делают что-то, чего они, очевидно, никогда не сделают в реальной игре. Это не просто какой-то «скручиватель мышц», который не поможет в будущем, верно? Они тренируются таким образом, чтобы определенным образом накачать мышцы. Точно так же вам нужно знать, какие «мышцы программирования» вы пытаетесь развить, решая конкретную задачу в качестве упражнения.
Я разгадываю всевозможные головоломки, потому что это делает процесс обучения более интересным и сложным. Иногда я решаю ту же головоломку, что и пару месяцев или недель назад, просто чтобы посмотреть, действительно ли то, что я пытался выучить, усвоилось. Помимо упражнений в решении проблем, я также тренирую определенные навыки программирования. Последние несколько недель я изучаю Kotlin, поэтому я изучаю новые программные конструкции и идиомы и очень сознательно применяю их в решениях, которые создаю.
В вашем случае я бы сказал, что вы могли бы попрактиковаться в следующих областях:
<р>1. Тестирование и написание модульных тестов для ваших программ2. Разбивка вещей на более мелкие части. Прямо сейчас у вас есть все в основном методе, который является очень плохой привычкой. Если вы продолжите практиковать таким образом, ваше развитие как программиста будет продвигаться очень медленно. Как только вы научитесь создавать свои собственные методы, вы больше не должны помещать все в main.
3. Возможно, попробуйте решить эту проблему с помощью потоков, чтобы узнать о них больше.
ByteArrayInputStream содержит внутренний буфер, содержащий байты, которые могут быть прочитаны из потока. Внутренний счетчик отслеживает следующий байт, который будет предоставлен методом чтения.
Закрытие ByteArrayInputStream не имеет никакого эффекта. Методы этого класса можно вызывать после закрытия потока без генерации IOException.
Сводка по полю
| Модификатор и тип | Поле и описание |
|---|---|
| защищенный байт[] | buf |
Сводка конструктора
Краткое описание метода
| Модификатор и тип | Метод и описание |
|---|---|
| int | available() |
Методы, унаследованные от класса java.io.InputStream
Методы, унаследованные от класса java.lang.Object
Детали поля
Массив байтов, предоставленный создателем потока. Элементы от buf[0] до buf[count-1] — это единственные байты, которые можно прочитать из потока; элемент buf[pos] — следующий считываемый байт.
Индекс следующего символа для чтения из буфера входного потока. Это значение всегда должно быть неотрицательным и не превышать значение count . Следующим байтом, который будет считан из буфера входного потока, будет buf[pos] .
Текущая отмеченная позиция в потоке. Объекты ByteArrayInputStream по умолчанию помечаются в нулевой позиции при создании. Они могут быть отмечены в другом месте буфера с помощью метода mark(). Текущая позиция буфера устанавливается в эту точку методом reset().
Если метка не была установлена, то значением метки является смещение, переданное конструктору (или 0, если смещение не было указано).
количество
Индекс на единицу больше, чем последний допустимый символ в буфере входного потока. Это значение всегда должно быть неотрицательным и не превышать длину buf. Это на единицу больше, чем позиция последнего байта в buf, который когда-либо может быть прочитан из буфера входного потока.
Сведения о конструкторе
ByteArrayInputStream
Создает ByteArrayInputStream, чтобы он использовал buf в качестве буферного массива. Буферный массив не копируется. Начальное значение pos равно 0, а начальное значение count равно длине buf .
ByteArrayInputStream
Создает ByteArrayInputStream, который использует buf в качестве буферного массива. Начальное значение pos равно смещению, а начальное значение count равно минимуму offset+length и buf.length. Буферный массив не копируется. Метка буфера устанавливается на указанное смещение.
Сведения о методе
Читает следующий байт данных из этого входного потока. Байт значения возвращается как int в диапазоне от 0 до 255. Если байт недоступен из-за достижения конца потока, возвращается значение -1.
Этот метод чтения нельзя заблокировать.
Считывает до len байтов данных в массив байтов из этого входного потока. Если pos равно count , то возвращается -1 для обозначения конца файла. В противном случае число k прочитанных байтов равно наименьшему из значений len и count-pos . Если k положительное, то байты от buf[pos] до buf[pos+k-1] копируются в b[off] до b[off+k-1] способом, выполняемым System.arraycopy . Значение k добавляется в pos и возвращается k.
Этот метод чтения нельзя заблокировать.
Пропускает n байтов ввода из этого входного потока. Меньшее количество байтов может быть пропущено, если достигнут конец входного потока. Фактическое количество k байтов, которые нужно пропустить, равно наименьшему из n и count-pos . Значение k добавляется в pos и возвращается k.
доступно
Возвращается значение count - pos , которое представляет собой количество байтов, оставшихся для чтения из входного буфера.
ОтметитьПоддерживается
Проверяет, поддерживает ли этот InputStream отметку/сброс. Метод markSupported класса ByteArrayInputStream всегда возвращает значение true .
Установите текущую отмеченную позицию в потоке. Объекты ByteArrayInputStream по умолчанию помечаются в нулевой позиции при создании. Этим методом они могут быть помечены в другом месте буфера.
Если метка не была установлена, то значением метки является смещение, переданное конструктору (или 0, если смещение не было указано).
Примечание. ReadAheadLimit для этого класса не имеет значения.
сбросить
Сбрасывает буфер в отмеченную позицию. Отмеченная позиция равна 0, если не была отмечена другая позиция или в конструкторе не было указано смещение.
закрыть
Закрытие ByteArrayInputStream не имеет никакого эффекта. Методы этого класса можно вызывать после закрытия потока без генерации IOException.
- Обзор:
- Вложенные | | |
- Подробности: | |
Сообщите об ошибке или функции.
Дополнительные справочные материалы по API и документацию для разработчиков см. в документации по Java SE. Эта документация содержит более подробные описания, предназначенные для разработчиков, с концептуальными обзорами, определениями терминов, обходными путями и примерами рабочего кода.
Авторские права © 1993, 2020, Oracle и/или ее дочерние компании. Все права защищены. Использование регулируется условиями лицензии. Также ознакомьтесь с политикой распространения документации.
Java является статически типизированным, а также строго типизированным языком, поскольку в Java каждый тип данных (например, целое, символьное, шестнадцатеричное, упакованное десятичное и т. д.) предопределен как часть языка программирования, а все константы или переменные, определенные для данной программы, должны быть описаны одним из типов данных.
Типы данных в Java
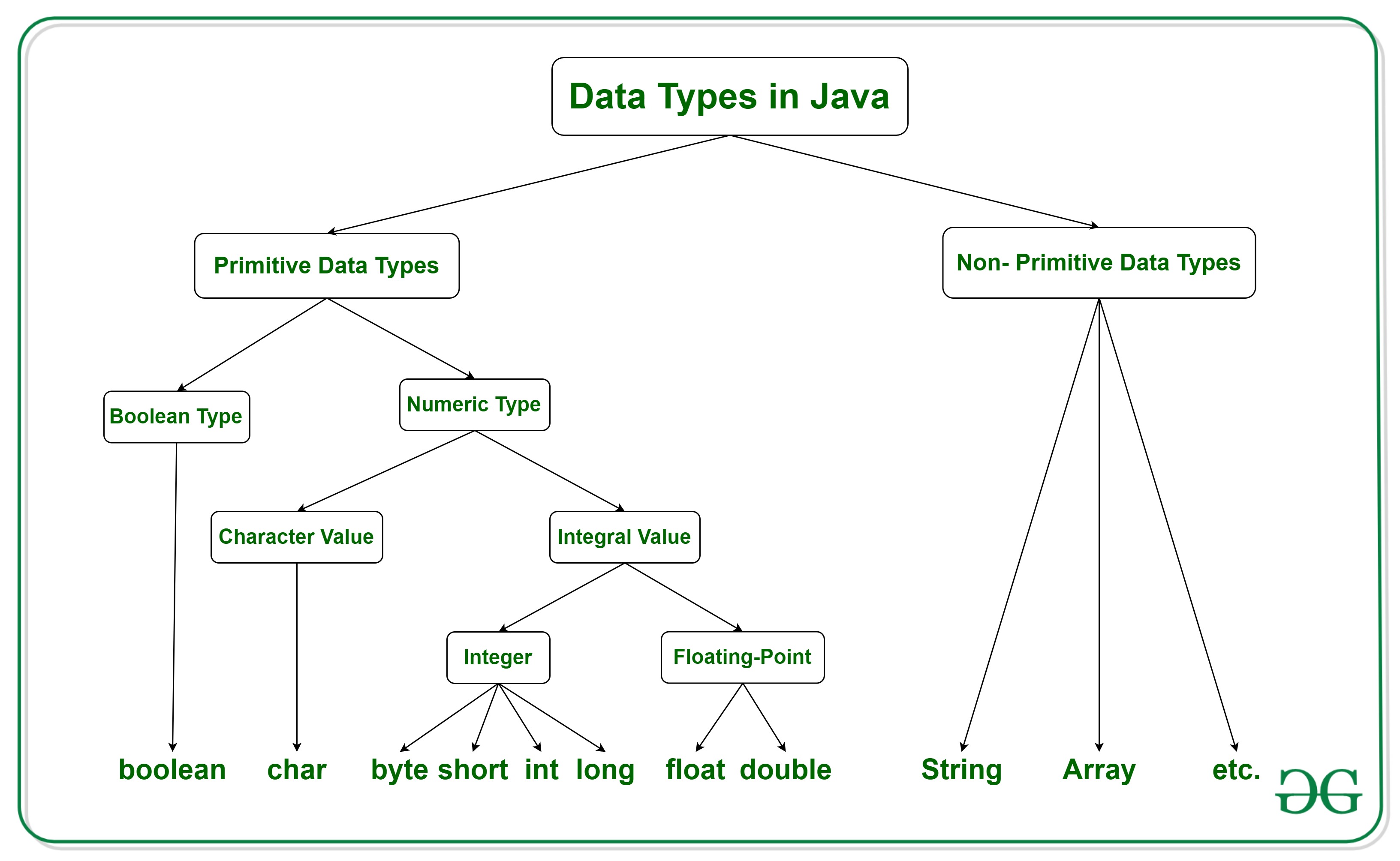
- Примитивный тип данных: например, boolean, char, int, short, byte, long, float и double.
- Непримитивный тип данных или объектный тип данных: например, строка, массив и т. д.
Примитивный тип данных
Примитивные данные представляют собой только отдельные значения и не имеют особых возможностей.
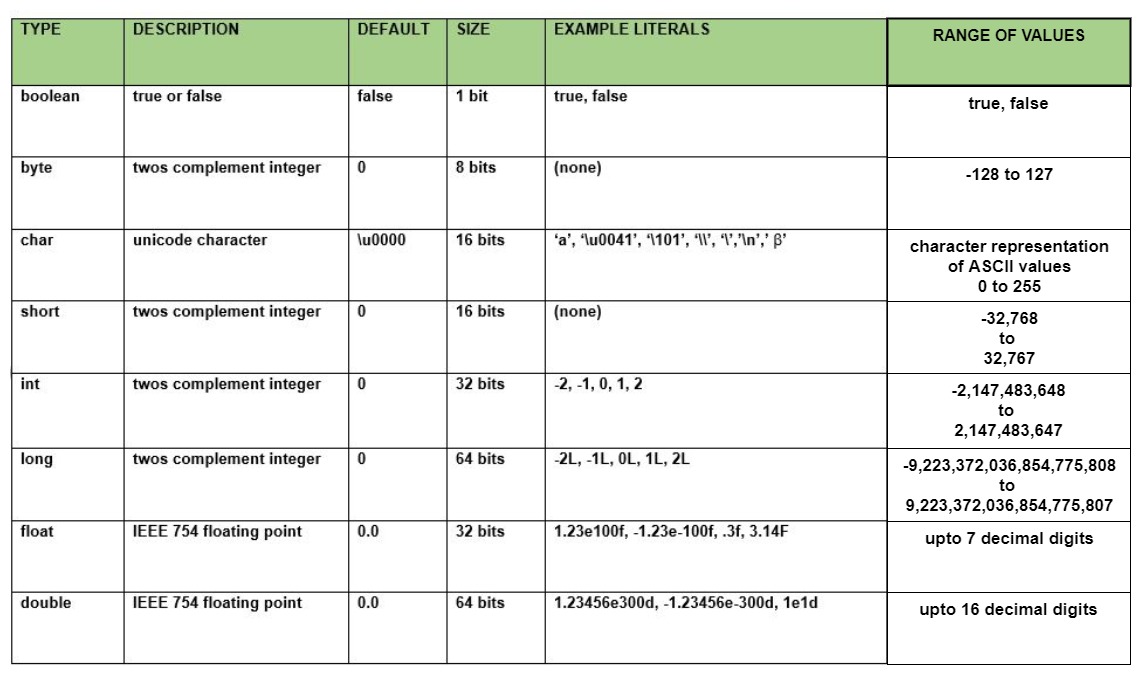
Типы примитивных типов данных
<р>1. boolean: логический тип данных представляет только один бит информации, истинный или ложный, но размер логического типа данных зависит от виртуальной машины. Значения типа boolean не преобразуются явно или неявно (с приведениями) в какой-либо другой тип. Но программист может легко написать код преобразования.Синтаксис:
Размер:
Значения:
Значение по умолчанию:
Синтаксис:
Размер:
Значения:
Значение по умолчанию:
<р>3. short: тип данных short представляет собой 16-разрядное целое число в дополнении до двух со знаком. Как и в случае с byte, используйте short для экономии памяти в больших массивах в ситуациях, когда экономия памяти действительно имеет значение.Синтаксис:
Размер:
Значения:
Значение по умолчанию:
<р>4. int: это 32-битное целое число в дополнении до двух со знаком.Синтаксис:
Размер:
Значения:
Значение по умолчанию:
<р>5. long: тип данных long представляет собой 64-битное целое число с дополнением до двух.Примечание. В Java SE 8 и более поздних версиях мы можем использовать тип данных int для представления 32-битного целого числа без знака, значение которого находится в диапазоне [0, 2 32 -1]. Используйте класс Integer, чтобы использовать тип данных int как целое число без знака.
Синтаксис:
Размер:
Значения:
Значение по умолчанию:
<р>6. float: тип данных float представляет собой 32-разрядное число с плавающей запятой одинарной точности IEEE 754. Используйте float (вместо double), если вам нужно сэкономить память в больших массивах чисел с плавающей запятой.Примечание. В Java SE 8 и более поздних версиях вы можете использовать тип данных long для представления беззнакового 64-битного типа long, который имеет минимальное значение 0 и максимальное значение 2 64 -1. Класс Long также содержит такие методы, как сравнение беззнакового, деление беззнакового и т. д. для поддержки арифметических операций для беззнакового длинного числа.
Синтаксис:
Размер:
Значения:
Значение по умолчанию:
<р>7. double: Тип данных double представляет собой 64-разрядное число с плавающей запятой двойной точности IEEE 754. Для десятичных значений этот тип данных обычно используется по умолчанию.Синтаксис:
Размер:
Значения:
Значение по умолчанию:
<р>8. char: тип данных char представляет собой один 16-битный символ Unicode.Примечание: типы данных float и double были разработаны специально для научных вычислений, где допустимы погрешности аппроксимации. Если точность является наиболее приоритетной задачей, рекомендуется не использовать эти типы данных и вместо этого использовать класс BigDecimal. Подробнее см. здесь: Ошибки округления в Java
Синтаксис:
Размер:
Значения:
Значение по умолчанию:
Почему размер char равен 2 байтам в java.
Юникод определяет полностью международный набор символов, который может представлять большинство письменных языков мира. Это объединение десятков наборов символов, таких как латинский, греческий, кириллица, катакана, арабский, и многие другие.
Непримитивный тип данных или ссылочные типы данных
-
: Строки определяются как массив символов. Разница между массивом символов и строкой в Java заключается в том, что строка предназначена для хранения последовательности символов в одной переменной, тогда как массив символов представляет собой набор отдельных объектов типа char.
- В отличие от C/C++, строки Java не заканчиваются нулевым символом.
Ниже приведен основной синтаксис для объявления строки в языке программирования Java.
Синтаксис:
Пример:
- Модификаторы: класс может быть общедоступным или иметь доступ по умолчанию (подробности см. в Спецификаторах доступа для классов или интерфейсов в Java).
- Имя класса. Имя должно начинаться с начальной буквы (по соглашению с заглавной).
- Суперкласс (если есть): имя родительского класса (суперкласса), если есть, которому предшествует ключевое слово extends. Класс может расширять (подкласс) только одного родителя.
- Интерфейсы (если есть): список интерфейсов, разделенных запятыми, реализованных классом, если таковые имеются, перед которыми ставится ключевое слово "реализует". Класс может реализовывать более одного интерфейса.
- Body: тело класса, заключенное в фигурные скобки, < >.
- Состояние: оно представлено атрибутами объекта. Он также отражает свойства объекта.
- Поведение: представлено методами объекта. Он также отражает реакцию объекта на другие объекты.
- Идентификация. Присваивает объекту уникальное имя и позволяет одному объекту взаимодействовать с другими объектами.
- Интерфейсы определяют, что должен делать класс, а не как. Это план класса.
- Интерфейс связан с такими возможностями, как Player, который может быть интерфейсом, и любой класс, реализующий Player, должен иметь возможность (или должен реализовать) move(). Таким образом, он определяет набор методов, которые должен реализовать класс.
- Если класс реализует интерфейс и не предоставляет тела методов для всех функций, указанных в интерфейсе, тогда класс должен быть объявлен абстрактным.
- Примером библиотеки Java является Comparator Interface. Если класс реализует этот интерфейс, его можно использовать для сортировки коллекции.
- В Java все массивы размещаются динамически. (обсуждается ниже)
- Поскольку в Java массивы являются объектами, мы можем определить их длину, используя длину члена. Это отличается от C/C++, где мы находим длину, используя размер.
- Переменная массива Java также может быть объявлена, как и другие переменные, с [] после типа данных.
- Переменные в массиве упорядочены, и индекс каждой начинается с 0.
- Массив Java также можно использовать как статическое поле, локальную переменную или параметр метода.
- Размер массива должен быть задан значением int, а не длинным или коротким.
- Прямым надклассом типа массива является Object.
- Каждый тип массива реализует интерфейсы Cloneable и java.io.Serializable.
Читайте также: